I have been having issues now for the last number of nights I have been out - Now SGP is totally unreliable on my system and nothing has changed since it last worked. I am at a total loss and really could do with some help before I chuck in the towel. I need reliability, not what I have at the moment.
I started my sequence and managed 2 30minute subs - In between times I had numerous recoveries due to cloud.
My first worry was the dreaded SafeParse Double message in my log that has been unfathomable so far.
Then SGP went into recovery for no reason that I could see, there was no cloud. (its been useful sitting here watching it all go on when I would normally be in bed)
Then it managed to get going again and PHD wouldn’t lock onto the guide star and it wandered off the screen with the usual PHD message.
I manaully stopped the sequence so that it would plate solve again and PHD would restart … It did that bit and then didn’t hold the calibration in PHD, so that was it … game over.
Can ANYONE please take a look at the logs and try to help. I am at my wits end with this. I have done the following.
Reseated ALL USB cables, changed all cables including the EQMOD cable, Uninstalled and reinstalled PHD2 (now on the dev version), Uninstalled and reinstalled EQMOD. Image history has been disabled following from Ken’s suggestion before.
Sara’s issue are not isolated, there seems to be some issue between SGP, EQAscom and PHD2 - at least they are the common factors though software versions of SGP are different between the two system I have looked at.
Sara does need to post to the PHD2 forum as PHD2 is not holding calibration though SGP and PHD2 integration is so tight these days they from a users perspective they are part of the same product.
This is a link to 5 SGP logs, 3 of which should the parsedouble error
I work closely with 10 to 15 users in setting up this software over a few different configurations and Sara and the logs attached are the only two seeing problems.
I do suspect some odd mis-configuration or USB issue but damned if I can see it.
Is there a way we can work though this, maybe with specific debug versions ?
swag72,
Could you please also post the PHD2 Guide Log from the session? You will find it in the same location as the phd2 debug log that you posted.
Andy
In your honor, I ran an entire night’s imaging with my region set to ES (Spain). Unfortunately it did not trigger any of these issues.
If you are interested we can provide a special build to you with temporary debugging that will help isolate the issue. Though your most recent log did not display this behavior. There are some SafeParseDouble issues, but they are in a different area of the sequence that your previous logs.
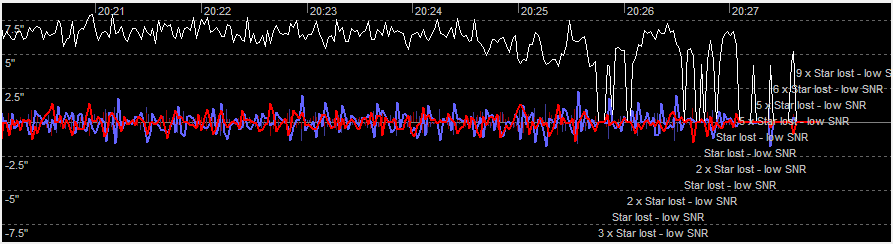
The reason is that PHD2 lost the guide star. From the PHD2 logs:
20:28:15.441 00.000 2112 Status Line 0: Star lost - low SNR
I wish I was more fluent in EQMOD, but I am not. It might be contributing to several issues.
The white line is the SNR, the red and blue are Dec and RA offsets of the guide star.
Plummeting SNR like that means that clouds came through.
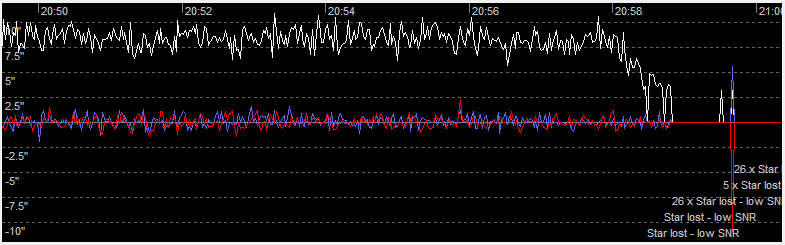
It happened again later around 20:58:
There were a couple incidents later, around 22:34 and 23:06 where it looks like the mount stopped responding to RA guide commands. Usually that indicates some kind of mechanical slippage like a slipping clutch or something like that. There are no errors in the phd2 debug log, so EQMOD was receiving the guide commands from phd2 and reporting success… more evidence of a possible mechanical issue, but we don’t really know for sure.
I don’t really understand what that means… could you elaborate? After calibrating at 23:07, it looks like guiding ran successfully until 23:58. Are you saying that the calibration was not expected?
BTW, the phd2 debug log on dropbox is truncated at 22:34. We’ll need to see the rest of the debug log to see what triggered the calibration at 23:07.
When this issue first started I changed my camera and guider cables for new Lindy ones. When this issue continued I didn’t for one minute think it would be a cable issue, having already changed them for new ones.
Last night I changed my guider cable for the last spare new cable i had and it appears to have solved the issue. My run last night worked perfectly.
So I can only assume that I was lucky enough to get a new duff cable… How lucky is that? I will confirm that this was the case on my next run… but I do believe this is sorted now.
I’d like to thank you all for your help and the amount of time you have put into this issue for me. I hope that you can understand that once the cables had been replaced, that wasn’t a place that I would naturally re-explore.
That really is unlucky, if it does turn out to be a fault with a new cable.
Are you using a Lodestar or Lodestar X2 for the guide camera? I know that the former has a delicate ZH cable socket (rather than the new RJ12) which was prone to failure.
Swag72, if you have the option I would encourage you to guide with your Lodestar using the Ascom pulse guide instead of the ST4 cable. Breaking cables on my Lodestar is the reason I tried pulse guiding via ascom, and I actually noticed a slight improvement in guiding. Plus you can ditch the ST4 cable all together and have one less cable to worry about.
Thanks for your thoughts Joel - They are much appreciated. I have been pulse guiding for years, in fact an ST4 cable has not been near the Lodestar in anger.